What does Funny Mean to a Robot?




Purpose
The purpose of this project is to demonstrate the implementation of a humanoid agent. In this case, the characteristic I decided to implement was the ability to recognize emotions in the facial expressions of another human.
What is it?
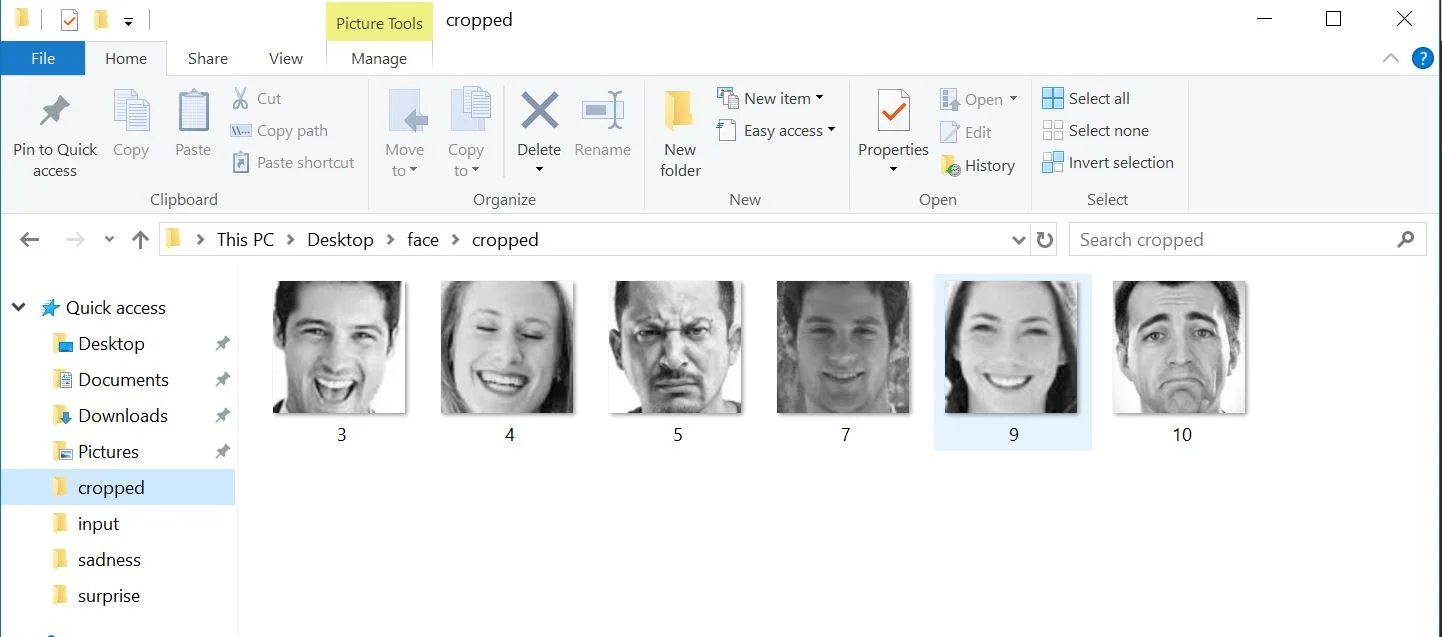
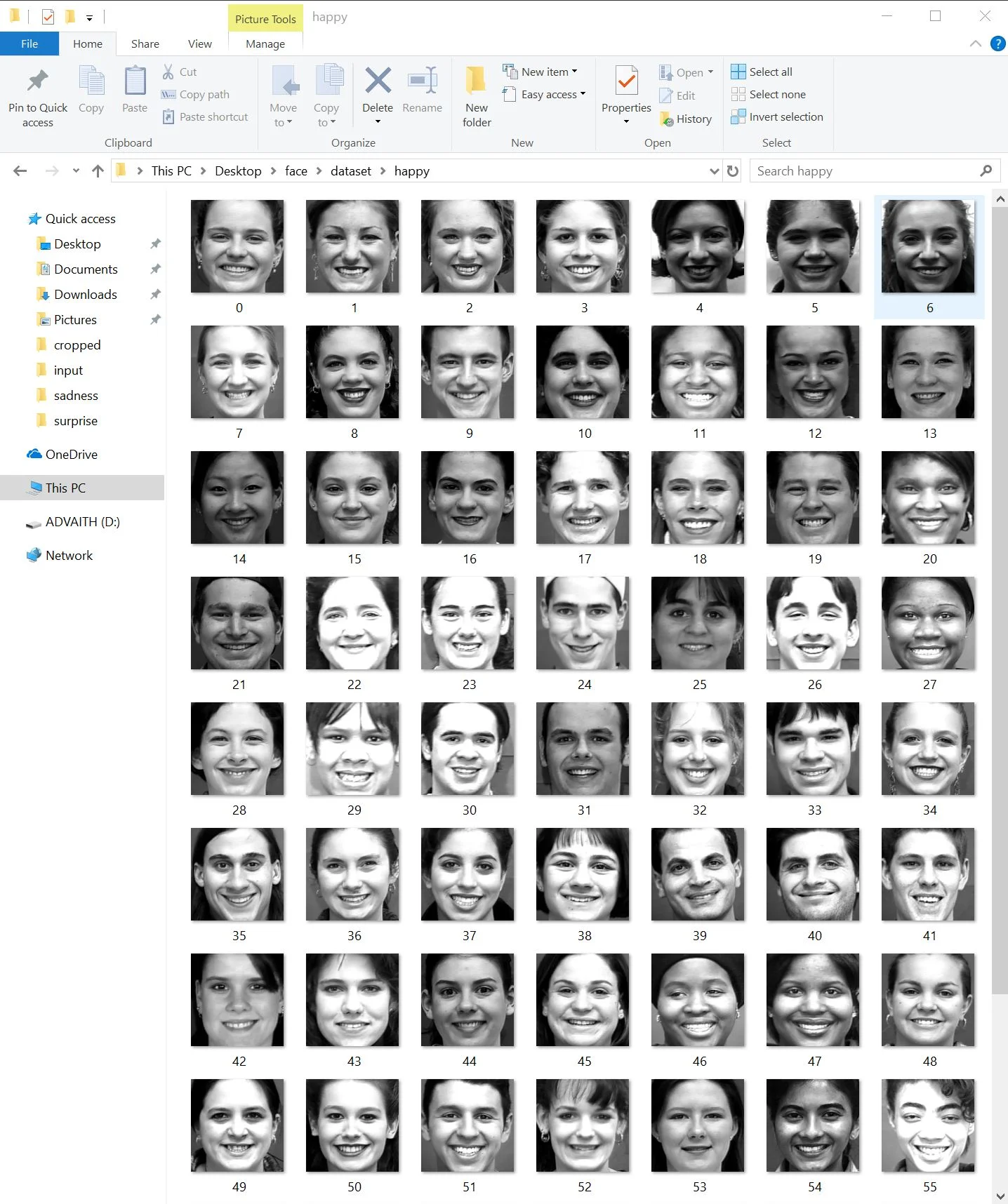
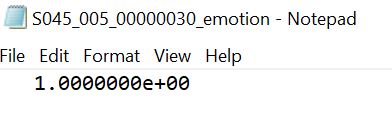
The program I have created involves training a facial recognition algorithm by using an existing data set. The database I used for the facial emotion detection is called the Cohn-Kanade dataset, which includes 379 pictures of test subjects and their related emotion values in text files.
The python script first sorts the pictures in the data set such that we get distinct categories for each emotion. Then, the script goes through each emotion and trains the built-in Fisher face recognition system which is included in OpenCV.
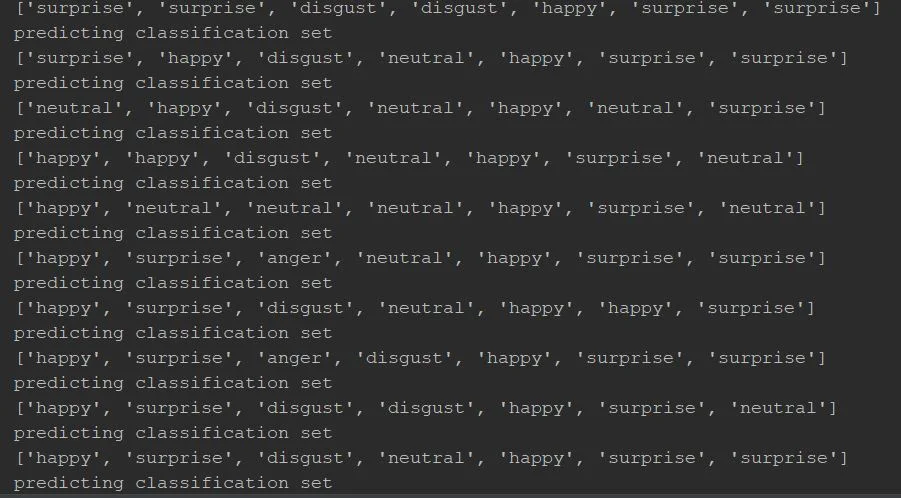
Finally, when this is done, it can use the momentum from the training data to make predictions about any input file you give the system. To operate this, one must put the pictures into a separate folder, on which a python script crops and gray-scales the image based on initial facial detection algorithms. This ensures that Fisher has a consistent resolution and landmark point correlation to work with.
As with any neural network, the results improve as the number of iterations increase. I currently run the training 20 times in order to make (slightly off) predictions about the input data. In the future, the system will need to be changed in order to accommodate for a more powerful workflow using Tensorflow or similar APIs.
How it Works
The program has 3 distinct steps:
1. Train
2. Predict
3. Repeat
For the training step, as mentioned above, the Cohn-Kanade dataset helps vastly with organized emotion recognition. The training must happen multiple times for each input image, as this helps the program learn what landmark points lead to each emotion. This is vastly inefficient, as it takes around 2 minutes to predict the emotions in 10 images. For live emotion detection, Tensorflow will definitely need to be used.
For prediction, the program then performs multiple iterations of the facial recognition algorithm on each input image. Once this is done, the predicted values are loaded into a list and passed as the output. The program uses a python library called glob in order to facilitate easy navigation of the file system in Windows.
The process must be repeated for optimum accuracy. When beginning, the accuracy is around 77.1%, which increases to 89% with 10 iterations.
What did not Work?
There were many problems with this project. First, getting OpenCV to work with external images from the dataset required creating a python script that helped to normalize the pixel values and dimensions of each image passed into the classifier. In order to overcome this, I had to test multiple times my script until it worked with OpenCV (it has memory limitations that restrict the number of pixels that can be processed at one time).
Next, the program can on average in a large input set predict the emotion of an image. This means that for 100 images passed in, 89 of them will be identified accurately. However, I worked with a small dataset of 5 images. This meant that the values I was getting were sometimes off. Although this can only be fixed with a more diverse training set or with a change of API, this issue requires more intense screening of the dataset.
Future Plans
The purpose of an algorithm that can tell the emotion of its user is to use it to build another data base. Specifically, its application to memes. Memes are funny images distributed through electronic means that bring joy to many people. However, the biggest question in the meme community is how to distinguish between a good and a bad meme. Obviously a good meme makes a large group of people smile. By using the emotion detection algorithm, I can create a GUI with which I can associate memes (images) with the emotions they cause (an integer). By doing so, I can create a parallel to the Cohn-Kanade dataset wherein I have a set of good memes vs the emotions they evoke.
With this training data, I can train a reddit bot which will use PRAW (Python Reddit API Wrapper) to webscrape relevant memes for future consumption.